
2月18日,DeepSeek团队发布了一项具有里程碑意义的技术成果——原生稀疏注意力机制(Native Sparse Attention,NSA)。
这一创新技术专为长文本训练与推理设计,通过算法优化与硬件对齐,显著提升了大语言模型在长上下文任务中的效率和性能。


DeepSeek创始人梁文锋不仅亲自参与了这项研究,还亲自提交了相关论文,其他研究人员来自DeepSeek、北大和华盛顿大学,其中第一作者Jingyang Yuan(袁景阳)是在DeepSeek实习期间完成的这项研究。
从时间上看,梁文锋是在周日16号提交的论文,然后在第二天,也就是昨天出席了民营企业座谈会。

革命性NSA注意力机制问世
根据最新发布的论文,NSA的核心亮点可以概括为以下两点:
1、动态分层稀疏策略:NSA采用了一种动态分层的稀疏策略,结合了粗粒度的Token压缩和细粒度的Token选择。这种策略既提升了效率,也保留了模型对全局长上下文的感知能力和局部精确性。
2、两大关键创新:算术强度平衡的算法设计与硬件优化,NSA通过精巧的算法设计,并针对现代硬件进行了实现优化,显著提升了计算速度;可训练的稀疏注意力,NSA支持端到端训练,减少了预训练计算成本,同时保持模型性能。
具体来看,NSA的核心在于动态分层稀疏策略,结合了粗粒度的Token压缩和细粒度的Token选择。这种策略不仅保留了全局上下文的感知能力,还兼顾了局部信息的精确性。
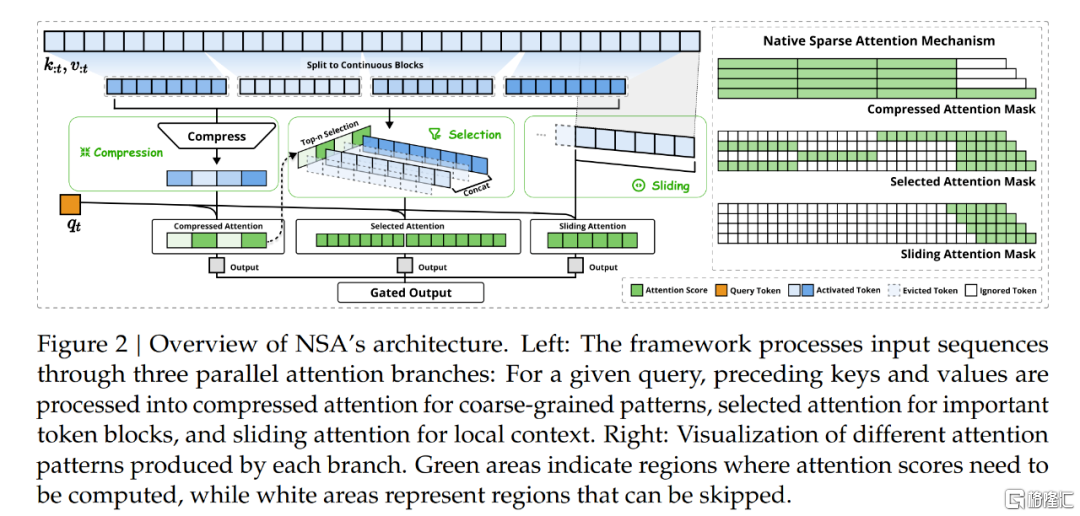
具体而言,NSA通过三种并行的注意力分支处理输入序列:压缩注意力(Compressed Attention)、选择注意力(Selected Attention)和滑动窗口注意力(Sliding Window Attention)。
压缩注意力负责捕获全局信息,选择注意力专注于关键Token块,而滑动窗口注意力则处理局部上下文信息。三个分支的输出通过门控机制聚合,从而实现高效的长文本建模。
此外,NSA还引入了算术强度平衡的设计,针对现代硬件进行优化,显著提升了计算速度。通过端到端的可训练性,NSA减少了预训练计算量,同时保持了模型性能。
这些创新使得NSA在长上下文任务中表现出色,特别是在处理64k长度的序列时,解码、前向传播和反向传播的速度提升最高可达11.6倍。

有网友说这就像给Transformer装上了“曲率引擎°”。确实,这提升太离谱了!就连很多大佬都忍不住要感叹:这是把传统注意力机制按在地上擦啊!
实验结果显示,NSA在多个基准测试中均展现出卓越的性能。在通用基准测试、长文本任务和指令推理方面,使用NSA预训练的模型不仅性能超越了传统的全注意力模型,还在长上下文任务中展现出显著优势。
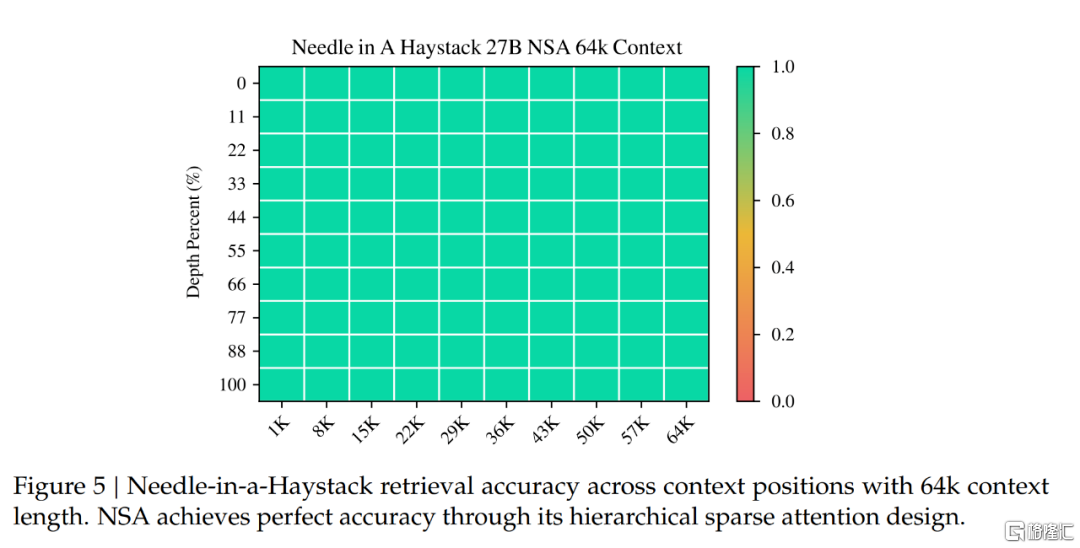
在64k上下文的“大海捞针”测试中,NSA实现了完美的检索准确率,证明了其在长序列处理中的高效性和准确性。
在硬件效率方面,NSA的表现同样令人瞩目。
在8卡A100计算集群上,NSA的前向传播和反向传播速度分别比全注意力快9倍和6倍。这种速度提升不仅源于硬件对齐的算法设计,还归功于分块内存访问模式和精细的循环调度,最大限度地利用了Tensor Core的计算能力。
通过减少内存访问量,NSA在长序列解码时的效率优势尤为明显,尤其是在处理128k上下文时,速度提升更为显著。
NSA的推出为大语言模型在长文本处理领域的应用带来了新的可能性。通过高效的长序列处理能力,模型可以直接处理整本书籍、代码仓库或多轮对话(如千轮客服场景),极大地扩展了大语言模型的应用边界。Gemini 1.5 Pro已展示了长上下文的潜力,而NSA的引入将进一步降低此类模型的训练与推理成本。
与此同时,NSA的硬件友好设计和训推一体化特性使其在实际应用中更具优势。
科技媒体指出,DeepSeek此次使用了Triton框架,而非英伟达专用库,这或许暗示了其在模型研发阶段已考虑适配更多类型的计算卡,为未来的开源和广泛应用奠定了基础。
同日早些消息,马斯克旗下XAI举行Grok 3发布会,对此,很快也有对比分析指出,与DeepSeek的技术创新路径形成鲜明对比的是,xAI选择了对工程规模的极致追求。

Grok3使用了20万块GPU集群,而未来的Grok4更是计划使用百万块GPU。这种“财大气粗”的策略虽然在短期内实现了对之前SOTA模型的反超,但投入产出比并不理想。
相比之下,DeepSeek通过算法优化和硬件对齐,以更低的成本实现了更高的性能提升,展现了其在技术破局中的独特优势。
附论文链接:https://arxiv.org/abs/2502.11089
主题测试文章,只做测试使用。发布者:北方经济网,转转请注明出处:https://www.hujinzicha.net/5574.html