


三分之一个世纪前,加拿大学者们提出了经典的MoE模型神经网络结构,在人类探索AI的「石器时代」中,为后世留下了变革的火种。
近十年前,美国硅谷的互联网巨擎在理论和工程等方面,突破了MoE模型的原始架构,让这个原本被置于学术高阁的理念,化身成为了随后AI竞争的导火索。
如今,后发优势再一次来到了大洋此岸,以华为为代表的中国科技企业,纷纷提出对MoE架构的优化重组方案。尤其是华为的MoGE架构,不仅克服了MoE负载不均衡及效率瓶颈的弊病,还能够降本增效,便于训练和部署。
AI之战远未终结,但正如在其他领域中「多快好省」的中国产业底色一样,大模型这棵生于西方长于彼岸的科技树,也同样会被东方智慧经手后,进化为更加普适和亲切的工具。
近期,虎嗅将打造《华为技术披露集》系列内容,通过一连串的技术报告,首次全面披露相关的技术细节。
希望本系列内容能为业界起到参考价值,也希望更多人能与华为一起,共同打造长期持续的开放协作生态环境,让昇腾生态在中国茁壮成长。
《华为技术披露集》系列 VOL.11 :RL后训练
在大模型竞赛白热化的当下,「强化学习后训练」已成为突破LLM性能天花板的核心路径。
爆火出圈的OpenAI o1、DeepSeek-R1等模型,背后都是依靠RL后训练点石成金。
相较于预训练阶段的「广撒网」式知识获取,RL 后训练通过驱动模型与外部环境进行动态交互,直接塑造了 LLM 在复杂任务中的推理效能。
当前,RL后训练阶段已经吃掉了训练全流程20%的算力,未来会飙升到50%,直接影响模型的性能和成本。
在传统RL后训练中,训练和推理得排队干活,也就说大量算力都在「摸鱼」。
对此,华为团队拿出「RL Fusion训推共卡」和「StaleSync 准异步并行」两大黑科技,把训练效率和资源利用率拉满。
· RL Fusion:让一张卡同时兼顾训练和推理两件事,资源利用率和吞吐翻倍。
· StaleSync:打破了同步限制,让集群扩展效率超90%,训练吞吐再提50%。
CloudMatrix超节点,就像大模型的「超级加速器」,让百亿、甚至千亿级模型训练更快更省。
至此,大模型强化学习训练正式迈入超节点时代。
RL后训练「算力黑洞」
如今,强化学习,已成为激活大模型推理思考能力的关键buff。
不论是语言模型的对话优化,还是多模态模型的复杂任务适配,RL后训练都在提升模型精度、泛化性、用户体验方面,发挥着不可替代的作用。
然而,这种性能提升的代价是巨大的算力需求。
尤其是在现有主流On-Policy算法下,训练与推理的严格交替导致了资源利用率低下。
总的来说,RL后训练作为大模型训练最后冲刺阶段,面临着两大不容忽视的挑战。
On-Policy算法的同步枷锁
在大模型后训练过程中,Actor模型的训练与推理(生成)过程构成主要负载。
在传统「训推分离」架构下,主流的On-Policy策略要求训练和推理任务交替执行,互相等待,导致大量计算资源处于闲置状态。
这种「轮流休息」的模式,在小规模集群场景下已然造成显着浪费,若在千卡/万卡集群中更是放大为「算力黑洞」,推高了LLM后训练成本。
因此,训推共卡技术,成为提升集群资源利用率的核心突破口。
大规模集群的扩展困境
另一方面,随着MoE模型普及,专家并行(EP)、张量并行(TP)、数据并行(DP)等多模型异构并行策略组合,使得任务调度复杂度呈指数级增长。
而现有框架在大规模集群中,难以让其实现高效协同,进而导致了扩展效率显着下降。
如何通过软硬协同打破资源瓶颈,释放潜在的红利,成为华为团队聚焦突破的关键方向。
RL Fusion:一卡干俩活,利用率吞吐翻倍
针对RL后训练资源利用率低的问题,华为团队深入剖析异构模型和多任务场景的负载特点,提出了创新性的RL Fusion训推共卡技术。
简单来说,就是让一张卡既做训练又做推理,效率直接翻倍。
RL Fusion支持训练推理共卡、全共卡等多种灵活部署模式(如图1),可实现推理阶段资源调度的精细化可控管理。
它还支持张量并行(TP)、数据并行(DP)、流水线并行(PP)等多维并行策略的动态无缝切换,实现计算资源「一箭双雕」,即在同一计算资源上执行Actor模型生成和训练2个任务。
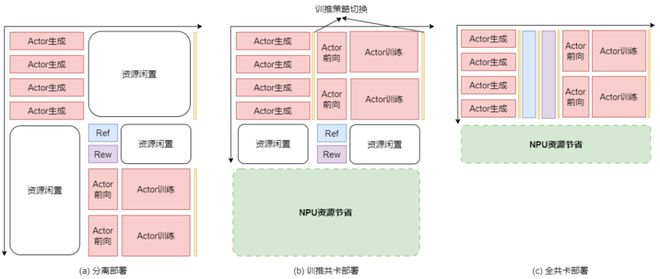
图1:训推分离、训推共卡、全共卡部署计算资源利用情况示意图
值得一提的是,在小规模场景下,RL Fusion还能把Reference及Reward模型的资源「榨干」,进一步实现「一箭四雕」,效率直接拉满。
此外,针对大规模高稀疏比MoE模型,华为通过对训推态内存进行极致分析,首次提出了训推内存0冗余切换,实现训推EP动态切换,如图2所示。
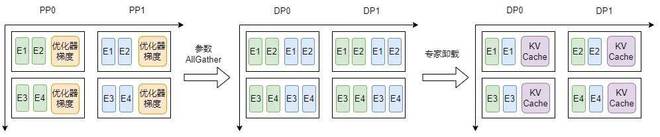
图2:MoE大模型训推EP动态变化示意图
在训练态及推理态切换过程中,通过「分桶」管理参数,可消除由于EP变化造成的冗余内存。
同时,推理时把训练的优化器及梯度,完全卸载到主机侧,尽可能将NPU内存留给推理态,保证长序列下推理阶段吞吐(如图3所示)。
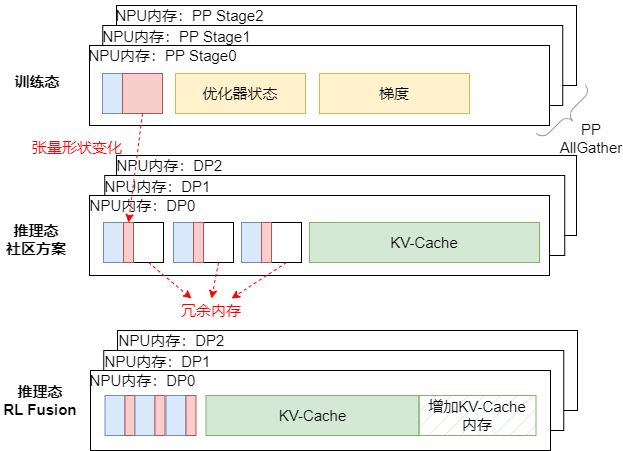
图3:MoE大模型训推内存0冗余切换技术示意图
不仅如此,通过对训推共卡中权重通信、内存加卸载进行系统性优化后,训推切换过程优化到秒级,快如闪电。
由此,RL Fusion能让强化学习后训练集群利用率倍增,成本省一大截。
StaleSync:水平扩展效率超90%,训练吞吐再提50%
针对大规模集群扩展性低的问题,华为团队摒弃全同步迭代方式,设计了准异步机制StaleSync(如图4所示)。
StaleSync机制能容忍梯度「陈旧性」,让不同RL阶段的任务在「陈旧度阈值」内并行执行。
这使得CloudMatrix 384超节点的水平扩展效率超90%。
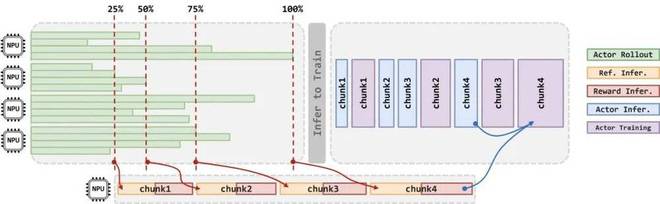
图4:StaleSync准异步并行技术示意图
这一创新得益于对RL计算任务的细致分析。
在RL训练中,研究团队发现,不同计算任务的算力需求各异。
基于这一特点,新的后训练系统结合了共置和分离架构的优势,平衡了各个RL计算任务的资源需求,从而提高了整体硬件资源的利用率。
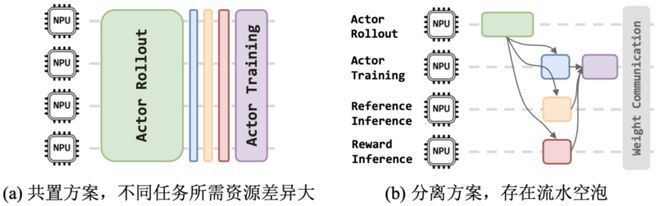
图5:共置/分离架构下同策训练方案示意图和缺点
此外,在Actor Rollout过程中,长尾样本的存在导致了效率的降低。
为了解决此问题,新系统引入了准异步调度机制:
当生成结束的样本达到一定阈值时,数据立刻流向下一阶段的计算任务,允许未完成的推理样本的训练存在一定滞后性,从而提高了整体后训练吞吐。
在保证模型精度的前提下,StaleSync方案使系统整体训练吞吐量提升了50%。
背后功臣:数据队列DistQueue
为了满足StaleSync的数据调度与管理要求,研究团队专门设计了分布式数据队列DistQueue。
DistQueue实现了不同计算任务之间数据的拆分、缓存与动态读取。
为了提高通信效率,DistQueue采取了分层数据传输与零冗余通信两项技术,缓解了数据系统压力。
以Pangu 718B-MoE训练并行策略为例(TP8,EP4,PP16),引入分层数据传输可将DistQueue的负载降低为 1/128,从而支持后训练规模的进一步扩展。
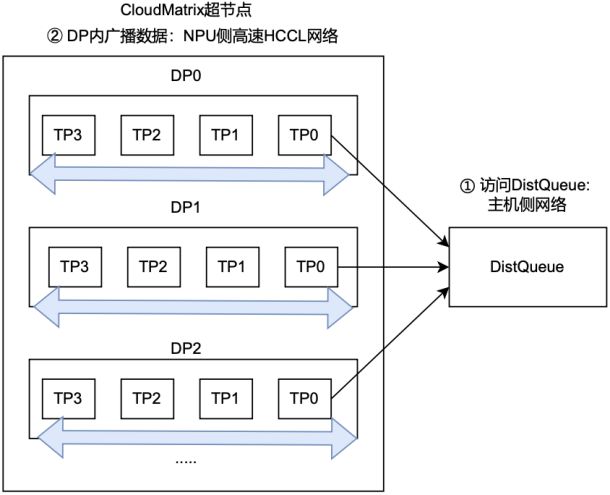
图6:分层数据传输技术示意图
在后训练中,传统的样本Padding补齐方案存在大量冗余通信,降低了通信效率。
对此,研究者引入零冗余通信技术,如图7所示:
首先将各个样本在序列维度进行拼接;
在各个进程收到数据后,再根据原始序列长度进行恢复。
这避免了Padding带来的额外通信,大大提升了通信效率。
在盘古长序列训练集实测,研究团队发现上述优化可降低80%以上的通信量,有效支撑大规模集群训练的扩展效率。
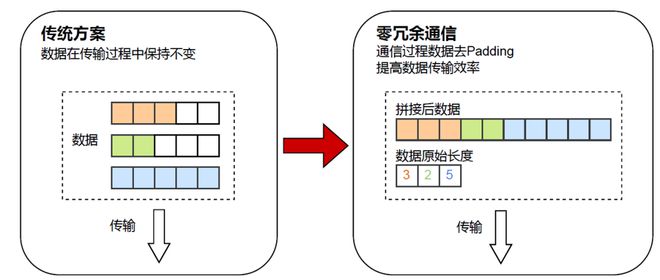
图7:DistQueue零冗余数据传输
实测:昇腾超节点见证效率跃升
RL Fusion与StaleSync的协同优化,形成了「资源复用+任务并行」的双重保障体系,显着提升了效率。
在RL后训练中,下表1展示了不同加速配置方案对整体性能提升情况。
RL Fusion训推共卡,能够消除RL后训练中模型级空泡,提高资源利用率,单个超节点吞吐提升了78.5%。
再结合StaleSync准异步技术,可以实现35k token/s吞吐效率,整体可提升1.5倍性能。
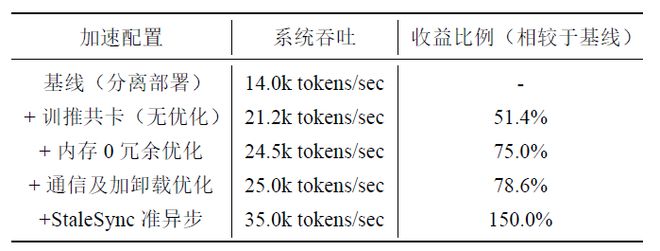
表1:单超节点RL后训练性能分析
表2展示了StaleSync对集群扩展性的提升。
当集群规模从1个超节点扩展至4个超节点时,StaleSync 的吞吐从35k tokens/s提升至127k tokens/s,扩展线性度达91%;而全同步方案在同等规模下吞吐仅从25k tokens/s 增至 85k tokens/s,线性度约为85%。
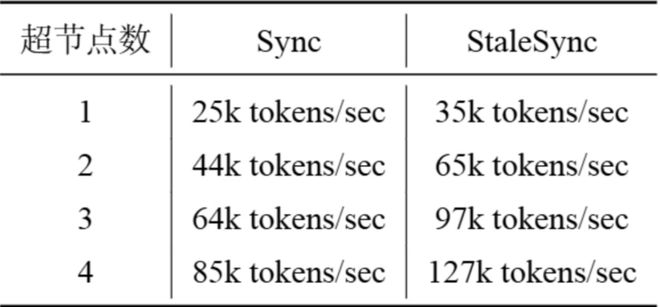
表2:RL后训练性能分析
在AI风起云涌的当下,RL后训练正成为大模型突围的关键,而效率是决胜的王牌。
昇腾超节点以RL Fusion和StaleSync两大杀招,攻克算力浪费和集群扩展的瓶颈,带来了高效、高扩展、高通用性的集群调度与融合方案。
一张卡干俩活、流水线永不停,单节点速度狂飙2.5倍,集群扩展效率突破90%。
它如同一台「加速引擎」,正为百亿、千亿级大模型的后训练注入强劲动力,点燃下一代AI效率革命的火花。
本内容为作者独立观点,不代表虎嗅立场。未经允许不得转载,授权事宜请联系 hezuo@huxiu.com
本文来自虎嗅,原文链接:https://www.huxiu.com/article/4430128.html?f=wyxwapp
主题测试文章,只做测试使用。发布者:北方经济网,转转请注明出处:https://www.hujinzicha.net/27249.html